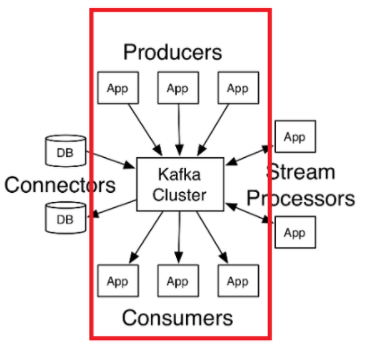
0. Kafka란?
- 아파치 카프카(Apache Kafka)는 LinkedIn에서 개발된 분산 메시징 시스템.
- 발행-구독(publish-subscribe) 모델을 기반으로 동작.
- 크게 producer, consumer, broker, connectors, streams processors 구성
1. 탄생배경
- 모든 시스템으로 데이터를 전송, 실시간 처리도 가능한 것.
- 데이터가 갑자기 많아 지더라도 확장이 용이한 시스템이 필요함
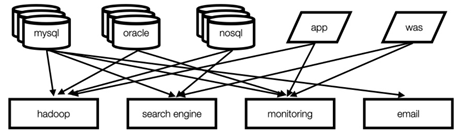
- Befroe Kafka
: 엔드투엔드 연결 방식의 아키텍쳐
: 데이터 연동의 복잡성 증가(하드웨어, 운영체제, 장애 등)
: 각기 다른 데이터 파이프라인 연결구조
: 확장에 엄청남 노력이 필요
- After Kafka
: 프로듀서/컨슈머 분리
: 메시지 데이터를 여러 컨슈머에게 허용
: 높은 처리량을 위한 메시지 최적화
: 스케일 아웃 가능

2. 서버 구성
- Kafka broker : 카프카 서버
- 3대 이상의 브로커로 클러스터 구성가능
- n개 브로커 중 1대는 컨트롤러 기능 수행
: 컨트롤러 기능
> 각 브로커에 담당파티션 할당 수행
> 브로커 정상 동작 모니터링
> 누가 컨트롤러 인지는 주키퍼에 저장
- 주키퍼 연동
: 메타데이터(브로커id, 컨트롤러id등) 저장
: 클러스터에서 구성 서버들끼리 공유되는 데이터를 유지하거나 어떤 연산을 조율하기 위해 사용 되는 오픈소스

3. 토픽(topic), 파티션(partition)
- 카프카 클러스터는 토픽이라는 곳에 데이터를 저장합니다.
- 카프카에 저장되는 메시지는 토픽으로 분류되고 토픽은 여러개의 파티션으로 나눠집니다.
- 파티션안에는 메시지의 위치를 나타내는 오프셋(offset)이 있는데, 이 오프셋 정보를 이용해서 가져간 메시지의 위치정보를 알 수 있습니다.

4. 컨슈머(consumer), 컨슈머그룹(consumer group)
- 컨슈머는 카프카 토픽에서 메시지를 읽어오는 역할을 합니다.
- 컨슈머 그룹은 하나의 토픽에 여러 컨슈머 그룹이 동시에 접속해 메시지를 가져올 수 있습니다.
5. Kafka Connect
- 데이터소스(DB) 를 카프카에 연동
6. Kafka streams processors
- 초기 사용 목적과는 다른 뛰어난 성능에 일련의 연속된 메시지인 스트림을 처리하는 데도 사용이 되기 시작했다. 이러한 스트림을 카프카는 Kafka Streams API를 통해 제공.
- 스트림 프로세싱(Stream Processing)은 데이터들이 지속적으로 유입되고 나가는 과정에서 이 데이터에 대한 일련의 처리 혹은 분석을 수행하는 것을 의미한다.
- 즉, 스트림 프로세싱은 실시간 분석(Real Time Analysis)이라고 불림.
- 배치(Batch) : 데이터를 한번에 특정 시간에 처리한다라는 특징 (스트림과 다름)
7. 해봄
- 단순 테스트 서버 설치 (windows)
: java sdk 설치
: kafka 다운로드 압축풀고 실행
> 주키퍼를 먼저 실행하고 카프카 실행

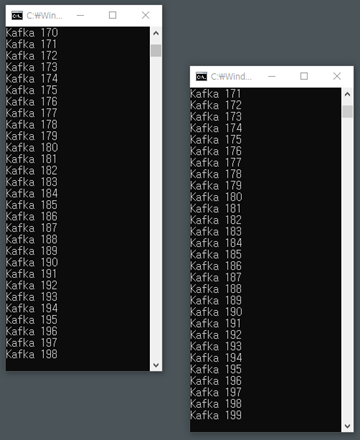
- .NET 테스트 개발(Confluent.Kafka 사용)
: 프로듀서
> 브로커명은 호스트명을 써줘야함.
> 토픽명만 정해서 값 전송
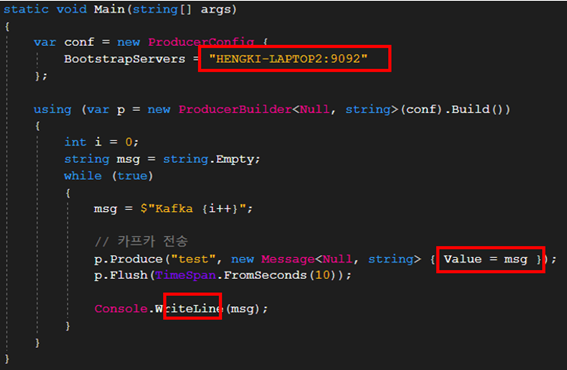
: 컨슈머
> 마찬가지로 브로커명은 호스트명을 써줘야함.
> 토픽명을 가지고 데이터 받아짐
> 그룹아이디를 지정해야함. (컨슈머가 속한 컨슈머 그룹을 식별하는 식별자)

: 실행